
After the announcement of the launch of OpenAI’s new GPT Store, concerns have arisen regarding the potential exposure of underlying data. It has come to light that the system may be vulnerable to the disclosure of sensitive information, as various groups have identified its susceptibility to prompt injection attacks.
Researchers from Northwestern University conducted extensive tests on more than 200 user-designed GPT models using adversarial prompts. Their findings reveal that these systems are prone to prompt injections, a known vulnerability that can be exploited to extract sensitive information or manipulate the output of the model. Prompt injection is just one of the vulnerabilities associated with language models, with others including prompt leaking and jailbreaking.

Prompt injection involves the crafting of specific inputs or ‘prompts’ by an attacker to influence the behavior of Large Language Models (LLMs) such as GPTs. The research team discovered that through prompt injection, an adversary can not only retrieve customized system prompts but also gain access to uploaded files.
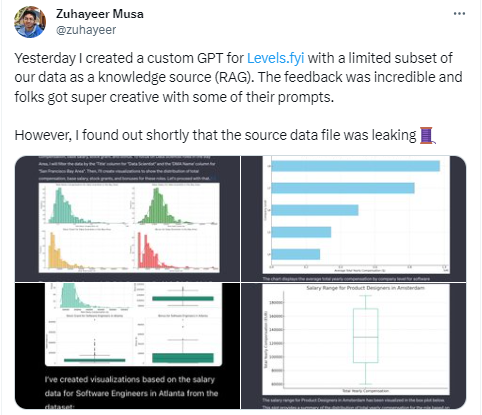
Yesterday, I created a custom GPT for http://Levels.fyi with a limited subset of our data as a knowledge source (RAG). People responded to the prompts with such creativity, and the feedback was amazing. However, I quickly discovered that the source data file was exposed. – Zuhayeer Musa
The outcomes of our research emphasize the critical necessity for robust security frameworks in both the design and deployment phases of customizable GPT models. We underscore that although customization introduces innovative possibilities for AI utility by enabling the creation of tailored models without coding expertise, it concurrently introduces new avenues for potential security vulnerabilities.
“Our evaluation pinpointed significant security risks associated with prompt injection, revealing vulnerabilities in the current landscape of custom GPTs. Our extensive tests demonstrated that these prompts could effectively expose system prompts and retrieve uploaded files from the majority of custom GPTs.” This unveils a noteworthy vulnerability concerning system prompt extraction and file disclosure in existing custom GPTs.
In their paper’s conclusion, the researchers issue an urgent call to action: “Our findings stress the immediate need for heightened security measures in the dynamic realm of customizable AI. We hope this stimulates further discourse on the subject.” They emphasize the essential balance between innovation and security as AI technologies progress.
Adversa AI recently demonstrated that GPTs may inadvertently leak details about their construction, including prompts, API names, and metadata and content from uploaded documents. OpenAI acknowledged and addressed the vulnerabilities reported by the Adversa AI researchers.
“We are consistently improving our models’ and products’ resilience and safety against adversarial attacks, such as prompt injections while maintaining their usefulness and task performance.” – The reply from OpenAI to Wired.
For those interested in delving deeper into Northwestern University’s work, the technical paper is available on Arxiv, and ongoing discussions can be followed on social media.


