
A new report from MIT has delivered a blunt message to the enterprise AI world: 95% of generative AI pilots produce no measurable return on investment.
The findings come from the State of AI in Business 2025 report, which analyzed more than 300 public enterprise deployments, included 150+ executive interviews, and tracked $30–$40 billion poured into AI pilots that never scaled.

The conclusion is hard to ignore. Most companies aren’t failing at experimentation. They’re failing at operationalization.
The “GenAI Divide”: Where Most AI Projects Stall
The report introduces what researchers call the GenAI Divide. It’s the gap between experimentation and real-world impact.
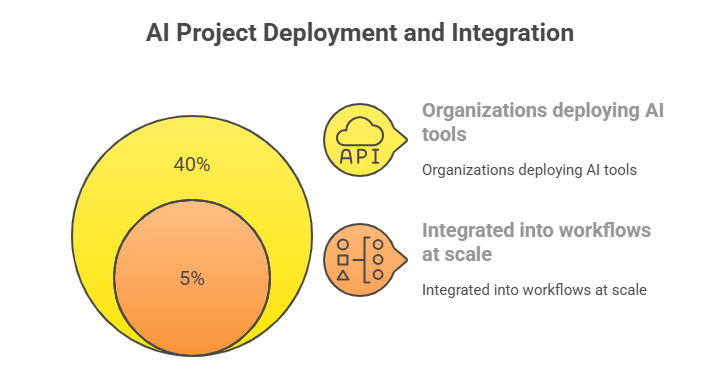
Here’s how it breaks down:
-
40% of organizations say they’ve deployed AI tools
-
Only 5% have integrated them into workflows at scale
-
The rest are stuck in pilot mode, unable to move forward or justify continued investment
This disconnect is already fueling skepticism. Some investors are openly questioning whether generative AI is forming a bubble. Others are betting that enterprise adoption has peaked before it ever truly began.
However, that conclusion may overlook the real issue.
Read More: 38 Generative AI Terms That Will Help You Understand the Tech
The Real Problem Isn’t Capability—It’s Trust
“The problem is being confidently wrong,” says Tanmai Gopal, co-founder and CEO of PromptQL.
Gopal, whose company collaborates with organizations such as OpenAI, Airbus, Siemens, and NASA, argues that enterprise AI isn’t failing because models lack power.
It’s failing because users don’t know when the system is wrong.
“If I can’t tell when an answer is unreliable,” Gopal explains, “every output becomes a liability instead of a time-saver.”
The Hidden Cost: The Verification Tax
Gopal calls this problem the verification tax.
Because generative AI systems present answers with high confidence—even when they’re incorrect—users are forced to manually double-check everything. That means:
-
Minutes saved by automation turn into hours of review
-
Productivity gains evaporate
-
Trust erodes quickly
In high-stakes environments like finance, healthcare, engineering, or government, one wrong answer can outweigh ten correct ones.
MIT’s data backs this up. Many pilots don’t fail dramatically. They quietly stall when employees stop using the tools because validating outputs takes longer than doing the work themselves.
Why Most Enterprise AI Never Learns
MIT researchers identified another core issue: most enterprise AI systems don’t improve over time.
They don’t:
-
Retain feedback
-
Adapt to real workflows
-
Learn from corrections
As a result, every interaction feels like starting from scratch.
Gopal sees this as a design failure. “If I don’t know why an answer is wrong—missing data, ambiguity, stale information—I can’t fix it. And if I can’t fix it, I won’t invest in it.”
This reframes the enterprise AI debate entirely. The issue isn’t model size or compute. It’s communication, humility, and learning loops.
Read More: Ready or Not, AI Is Becoming a Top Priority for Enterprises
How the 5% Are Doing It Differently
The small fraction of companies that are scaling AI share one trait: they prioritize reliability over bravado.
PromptQL is one example.
Instead of presenting AI output as definitive, the platform is built around what Gopal calls being “tentatively right.
What That Looks Like in Practice
-
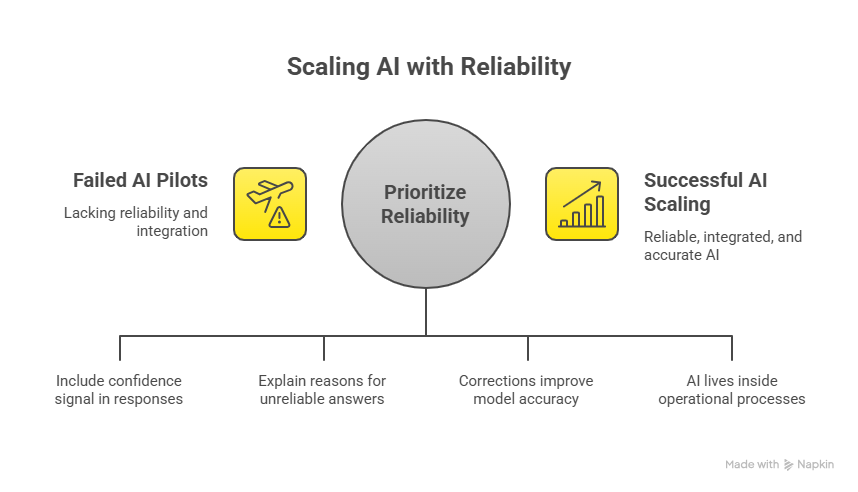
Uncertainty is quantified
Every response includes a confidence signal. If the system isn’t sure, it abstains instead of guessing.
-
Context gaps are surfaced
The system explains why an answer may be unreliable—whether due to missing data, ambiguity, or outdated inputs.
-
Corrections fuel learning
Every abstention or user correction feeds back into the model, creating an “accuracy flywheel” that improves over time.
-
AI lives inside workflows
Rather than a standalone chat tool, PromptQL integrates directly into contracts, procurement systems, and operational processes.
This approach aligns precisely with what MIT says is missing from most failed pilots.
Why “Tentatively Right” Wins in the Enterprise
This humility-first design has unlocked adoption where generative AI typically struggles most: regulated, high-risk, and mission-critical environments.
While most pilots stall, PromptQL is closing seven- and eight-figure contracts with Fortune 500 companies and public-sector organizations. These are the exact users MIT identified as least tolerant of confident errors.
The lesson is clear. Enterprise AI doesn’t need to sound smarter. It needs to be more honest.
Rethinking the AI Failure Narrative
The MIT report is right to highlight how widespread failure has been. But focusing only on the 95% that didn’t scale misses the more important insight: the 5% that did aren’t using AI the same way.
They demand systems that:
-
Admit uncertainty
-
Learn continuously
-
Integrate deeply into real work
-
Respect the cost of being wrong
Companies like PromptQL—and research efforts at firms like Anthropic—are proving that this approach works.
Read More: Top 6 Types of AI Models Shaping the Future of Technology
The Real Takeaway
Enterprise AI isn’t a bubble. But careless AI is.
The future belongs to systems that know their limits, communicate them clearly, and improve with every interaction. The organizations adopting that mindset are already pulling ahead—quietly, steadily, and at scale.
The GenAI divide is real. But it’s not permanent.

