
Microsoft Research Unveils rStar2 Agent: Smarter, Faster, and Cost Effective AI Training
Artificial intelligence is moving into a new phase, and Microsoft Research is leading the charge with its latest innovation. The company has introduced rStar2 Agent, a reinforcement learning framework designed to help AI models handle complex reasoning tasks at a fraction of the usual computational cost. Instead of simply making AI models “think longer,” this new system enables them to “Think smarter.”

A Shift from Thinking Longer to Thinking Smarter
Traditional large language models improve their reasoning by producing long chains of thought, essentially trying to solve problems by taking more steps. While this works for simpler tasks, it often backfires on challenging ones. A single mistake in a lengthy reasoning chain can derail the entire process, and internal self checks usually fail to catch those errors.
See More: Microsoft Cloud Faces Internet Disruptions After Red Sea Cable Cuts
Microsoft’s new approach changes the game. Rather than relying solely on extended reasoning, rStar2 Agent focuses on efficiency, adaptability, and tool usage. The model doesn’t just guess it validates its own work, runs tests, and refines answers based on real feedback.
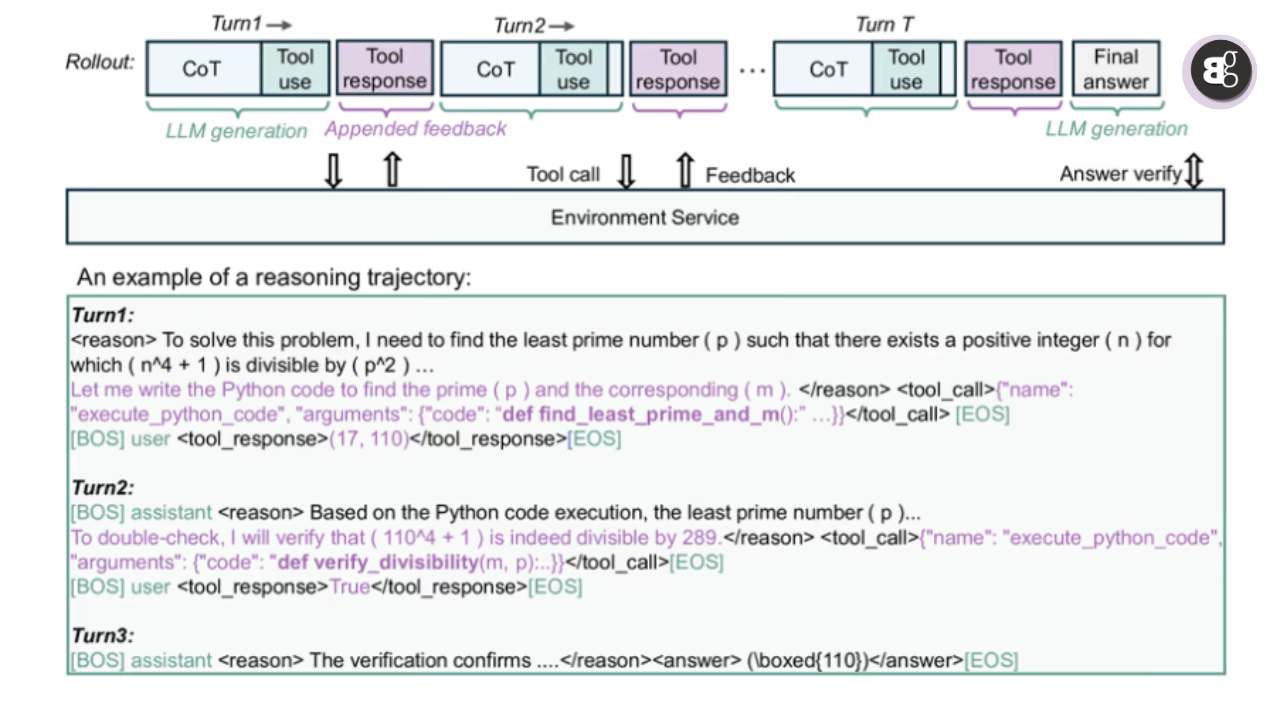
How rStar2 Agent Works
At its core, the framework uses agentic reinforcement learning, where the model acts as an agent that interacts with tools in a controlled environment. For example, by working with Python code, the AI can test calculations, check results, and refine its reasoning step by step. This makes the answers not only smarter but also more reliable.
Building this system, however, was not easy. Early prototypes struggled with practical issues: tool calls overwhelmed CPUs, GPUs stayed idle, and error messages from code distracted the model. To fix this, Microsoft developed an advanced infrastructure capable of handling 45,000 tool calls per step with extremely low latency. A load balancing scheduler ensures no GPU sits idle, making reinforcement learning training faster and smoother.
Smarter Algorithms, Cleaner Results
Another key innovation is Group Relative Policy Optimization with Resampling on Correct (GRPO RoC). Instead of rewarding all correct answers equally, this method filters out noisy or error prone solutions and prioritizes clean, high quality reasoning. It still keeps a variety of incorrect attempts for the model to learn from but ensures the training process doesn’t get sidetracked by messy or misleading outputs.
Read More: Microsoft’s new AI framework trains powerful reasoning models with a fraction of the cost
This balance means the AI learns to produce more concise, correct answers. For businesses, that translates to fewer mistakes, less time wasted correcting errors, and more predictable results. Imagine an automated code writing assistant generating scripts that run smoothly the first time that’s the promise of rStar2 Agent.
A Training Recipe That Saves Time and Compute
Microsoft also rethought how to train these models. Instead of throwing the AI straight into highly complex problems, the training starts with simpler instruction following and formatting tasks. Gradually, the difficulty increases, along with the response length. Thanks to this staged approach and the efficiency of GRPO RoC, a 14 billion parameter model was fully trained in just one week using significantly fewer computational resources than usual.
Small Model, Big Results
The test case is striking: a relatively modest 14B parameter model fine tuned with rStar2 Agent managed to outperform much larger rivals, including the 671B parameter DeepSeek R1, on challenging math benchmarks. Not only did it deliver higher accuracy, but it also generated shorter, more efficient answers, reducing cost and speeding up performance.
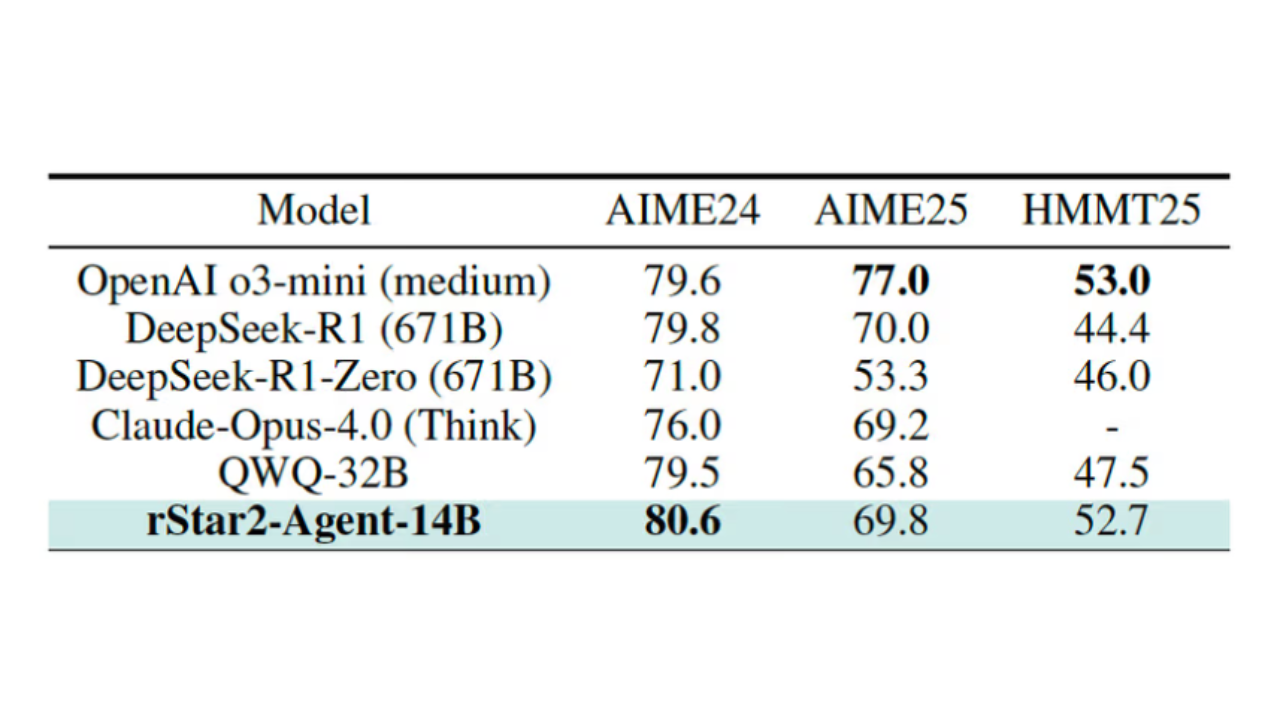
The results go beyond mathematics. Despite being trained mainly on math tasks, the model also excelled in science reasoning and tool usage benchmarks, proving that the skills learned could transfer to other domains like legal analysis, finance, and even drug discovery.
What This Means for Enterprises
For enterprises, the breakthrough points to a more sustainable path forward. Instead of pouring billions into ever larger AI models, businesses could get top level reasoning performance from smaller, open source systems fine tuned with rStar2 Agent. That means lower costs, faster deployment, and more reliable outcomes.
Li Lyna Zhang, one of Microsoft’s principal researchers, explained it best: “With GRPO RoC, the model learns to generate concise, correct code that runs successfully on the first try, keeping workflows smooth and predictable.”
Summary
While the framework has proven its strength in structured environments like Python, scaling it to more complex, real world tools will be the next challenge. Industries like healthcare, law, and finance rely on specialized systems full of “environment noise,” and adapting AI to handle that complexity will be the real test.
Still, the early signs are promising. rStar2 Agent shows that the future of AI won’t be about endlessly scaling models but about teaching them to reason smarter, adapt better, and work efficiently in enterprise settings.

